Experiments
Dr. C. George Boeree
A simple experiment starts out very much like correlation: You
have two sets of measurements and you look to see if there is a
relationship between them. You want to know if they
"co-relate." The two sets of measures are called variables.
Whatever it is, it has to vary in order for us to be interested in
measuring it!
The big difference between experiments and correlations is that, in
experiments, you actually manipulate
one of the variables. If you
are manipulating one of the variables, that means that the second
variable, if it "co-relates," was caused to do so by the variable you
manipulated! You can tell what the causal effects of the first
variable are on the second one -- something you can never be quite sure
of with a regular correlational study.
The two variables have specific names: the one you manipulate is
called the independent variable.
Think
of it like a radio
knob: You can turn the knob because it is, to a degree,
independent of the rest of the radio -- it turns! The other
variable is called the dependent
variable. If the experiment
shows that there is a relationship, then you know that it's this
variable that depends on the first one -- like the volume of your music
depends on where you set the volume knob.
If we measure the rotation of the knob (let's say somewhere between 0
and 10) and we set on each of the 10 settings, and then measure the
loudness (in decibels, perhaps), we would find (probably) a close to
perfect correlation. We use different kinds of statistics with
experiments, but the idea is still the same, only this time we can
conclude with considerable certainly that the setting of the knob
causes the volume to change. Duh.
But now let's consider a more interesting experiment: We want to
test a new drug to see if it improves people's ability to remember
things. Perhaps this drug might prove useful for helping
Alzheimer's patients. We have two variables: the drug and
memory. Each needs to be measured in some way. One common
approach is to measure the independent variable in an all or none
fashion: "0" would mean no pill; "1" would mean taking a
pill. In a case like this, we usually call the "0" group the
control group. The "1"
group is called the experimental group
or
the treatment group.
Very simple.
(Sometimes, we let nature do the manipulation for us. For
example, nature has made some people male and some people female.
We are male or female long before we participate in some experiment, so
we can comfortably say that it will be our maleness or femaleness that
caused the results to some degree. This is called a subject variable. We
often include subject variables such as male/female in our experiments
because they are free and easy, and give us just a little more
information.)
The other variable in our memory pill experiment is a bit
trickier: Perhaps we will need to develop some kind of memory
test. Let's say we quickly show people 10 items, and then ask
them to see how many of them they can remember. They can then get
a score between 0 (nothing remembered) and 10 (all remembered).
Now we are set: We can give half the people a pill and half not,
then test them all on memory. Then we can see if there is a
"co-relation." If the pill works, then those getting the pill
will score high on the test, those who didn't will score less, and we
will know why: the pill!
Now of course things are a lot more complicated than this. First
of all, we probably have to determine exactly how strong the pills are
to be, how often they are to be taken, how long they need to be taken
before we do our memory test, and so on.
We also have to be very careful about all kinds of biases that might
creep into the experiment. First, we are going to want to be sure
that we will be able to generalize to the whole population. If we
chose very specific, special people for our experiment, then our
results might only apply to them, and not to all the other people that
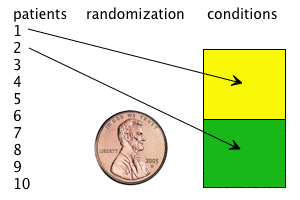
might benefit from the drug. So we need to have a random
sample. This means that we should try, as best as we can,
to pick
our subjects (the people in the experiment) randomly from the target
population. In this case, we might want to find a variety of
Alzheimer patients from all over the country. If that's not
possible, we should try at least to pick from a large group in a random
fashion.
Also, it would be a bad experiment if we allowed ourselves to pick some
people to be in the control group and others in the experimental group
on the basis of some quality they had. For example, if we gave
the pill to 20 women and used 20 men as the control group, then we
won't know if the pill helps everyone, or if there is something about
men and women that makes them better or worse at memory (something that
is actually a real issue!). So we have to have random assignment
to conditions.
All this randomization, and we should be set, right? Wrong.
There is till experimenter bias and subject bias to throw things
off. Subject bias
happens when the people in your experiment have
some kind of clue of what's going on and what is expected. A
person who knows that the pill they are taking is supposed to improve
their memory may try harder to remember, for example.
On thing to do is to keep the subjects in the dark. Don't tell
them what the pill is all about. Don't tell them what the memory
test is all about. There can be an ethical problem here, and we
often try to overcome that by asking the volunteers to sign a waiver
and debriefing them afterwards, telling them how we fooled them.
We also will want to give the people in the "0" condition some kind of
pill, so that everyone is at least taking something, and no one knows
who is and who is not getting the real pill. Fake pills are
called placebos, and we often
extend that term to cover all kinds of
fake control conditions. If we want to know the effects of
watching a violent movie, for example, we might have the control group
watch a romantic comedy, so they are at least doing the same kind of
activity.
There is also experimenter bias,
and
this can be even more damaging
than subject bias! You know how you want your study to come out,
no matter how cool and objective you pretend to be. You may be
giving subtle hints to your subjects, unintentionally. For
example, you might give the people who took the pill just a tiny
fraction more time to answer than you give the others. The only
way to control this is to make sure that you are in the dark,
too.
Arrange things to make sure that you (and any assistants you may have)
don't know which people took the
real pill and which took the placebo, for example.
When we combine both approaches, we call the experiment a
double-blind: Both
subjects and experimenters were "blind" to the
conditions. Nowadays, anything but a double-blind experiment is
treated with suspicion! Unfortunately, most experiments
concerning therapy or educational techniques cannot be double-blind, so
many important studies are not as strong as we would like them to be.
In our example, the statistics we use will look at the
differences in the scores of the control group and the experimental
group. Each group will have it's mean (average) as well as a
standard deviation (how spread out the test scores are). The
statistics will determine whether or not the differences between the
two group are likely to be significant
or more likely to be the results
of chance.
Other studies might use statistics very similar to correlation.
If, for example, we measure memory in 20 Alzheimer's patients before we
start them on our new pill, and then give them another test after
they've been on the pill for a month, then we can compare the two
measurements as if we had measured the length of their feet and their
shoe size.
There are dozens of variations of experiment design and of the
statistics we can use, each with their own advantages and
disadvantages. Psychology students are traditionally well trained
in statistics and experimental design, and they sometimes go on to
careers involving data gathering and testing for companies,
organizations, or the government. And some go on to do
experiments in psychology itself!
© Copyright 2005, C. George Boeree